





AB Testing
Jul 18, 2022
Experimentation is HARD!
How to accurately interpret your data

Drew Marconi

I was speaking the other day to one of my marketing colleagues, let’s call her Linda. She’s very bright, understands the value of data, and data plays a role in most of her decisions on a daily basis. Like Linda, you are also smart and data-driven, but how can you be sure you’re interpreting the data correctly?
A "Successful" Marketing Campaign
Let’s take an example I encountered recently: you run a retargeting campaign on users that interacted with you, left an email, but didn’t convert. You split the group in two: Group A gets a friendly reach out and Group B gets a 10% discount to sweeten the deal. Fast forward a week, and Group B has nearly twice as many conversions as A. The discount worked!
Or did it?
It depends… let’s say your groups each had 200 people in them, that seems like a lot. So in A 3 purchased (1.5%), and in B 5 people did (2.5%). On the surface, the discount caused a near doubling in conversion. How do you know whether or not that was just random chance? What if the discount had no effect, and just a few more people in Group B happened to purchase, just… because? How would you know?
Sample Size Matters
Statistics! Spoiler alert -- the outcome of the described has a 50% chance of being totally lucky. Even though your conversion increased from 1.5% to 2.5%, you can’t really glean anything from this experiment!!
Let’s understand this concept, which was first introduced by Jacob Bernoulli in the 17th century and is known as the Bernoulli Principle. Let’s say you flip a coin 4 times, 2 heads and 2 tails. That would make sense, because you know it’s 50/50. What if the outcome was 1 head and 3 tails, would you be surprised? Not really, that seems totally reasonable. And according to Bernoulli, that result of 25% has a degree of uncertainty, and a pretty large degree of uncertainty because you only have 4 samples, or flips, to choose from.
The statistics to describe this uncertainty, or standard error, of a Bernoulli distribution (What are the chances that X happens?) is as follows:
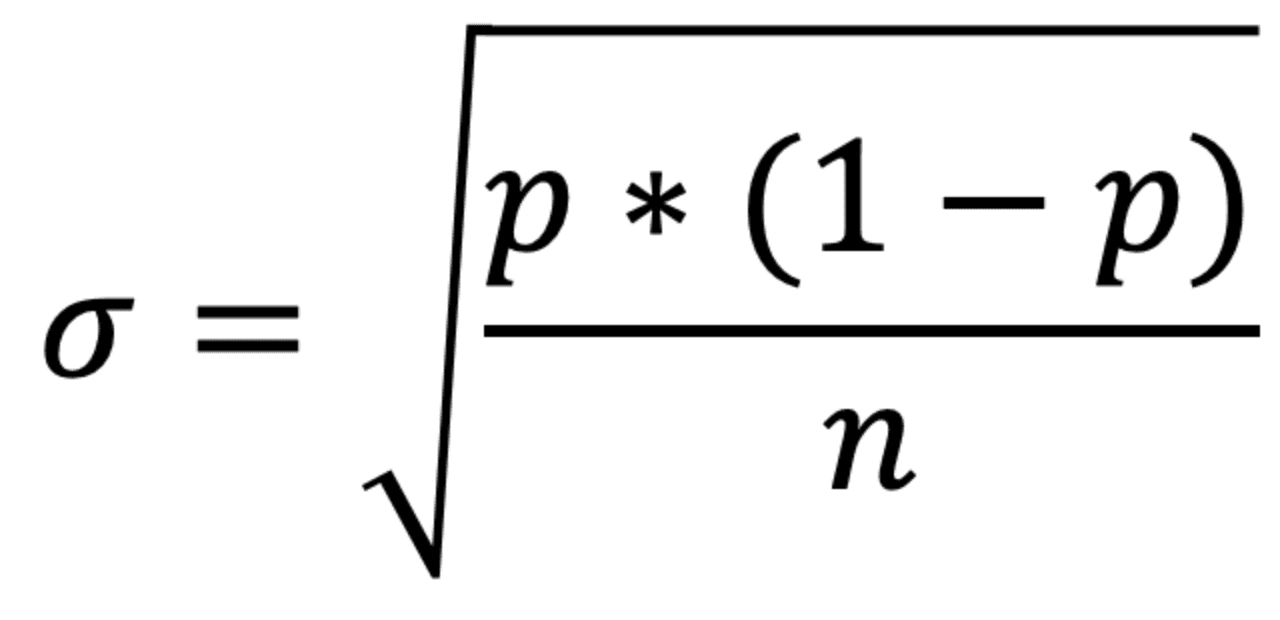
where p is the observed probability, and n is the number of trials. The intuition here is that with more trials, n, the standard error, or uncertainty, decreases thus increasing your confidence in the result. If you want 95% confidence, that’s +/- 1.96 sigmas. Let’s see this play out with our example...
Flip your coin a few more times, now you have 20 trials and your uncertainty moves to +/- 22%. Flip a few more, with 100 trials your uncertainty is +/- 10% and by 1000 your uncertainty is +/- 3%. Still some room for error, which is why you can go to the casino and play 1000 hands of blackjack and still come out ahead.
Circling Back to Our Example
The statistics behind this aren’t complex to calculate or understand, but can be difficult to incorporate into your daily business. Remember that campaign we ran with the 1.5% and 2.5% conversion? Plug into our formula, and our 1.5% could be as high as 4%, and the 2.5% in Group B could be nearly zero, and our 5 conversions were lucky. Using a chi-square test, we can calculate a p-value of 0.49, meaning that there’s about a 50% chance the difference we saw in these groups was just chance.
Data can be super powerful, but sometimes it can seem more powerful than it is. Be careful and use your powers for good and not for evil!
Check out the Intelligems App and the Intelligems Blog for more great content.
AB Testing
Campaigns
Analytics



